Controllable and Explainable AI
Posted: Jan 8, 2024
Efforts to control and interpret the inner workings of AI models have grown significantly in recent years. This post provides a high-level overview of techniques discussed in recent papers.
Controlling AI Models
Controlling Generation
Generative models sample data from a distribution. Shiyu et al (2024) [1] categorizes the mechanisms for controlling generative models. Here is the taxonomy from the paper-
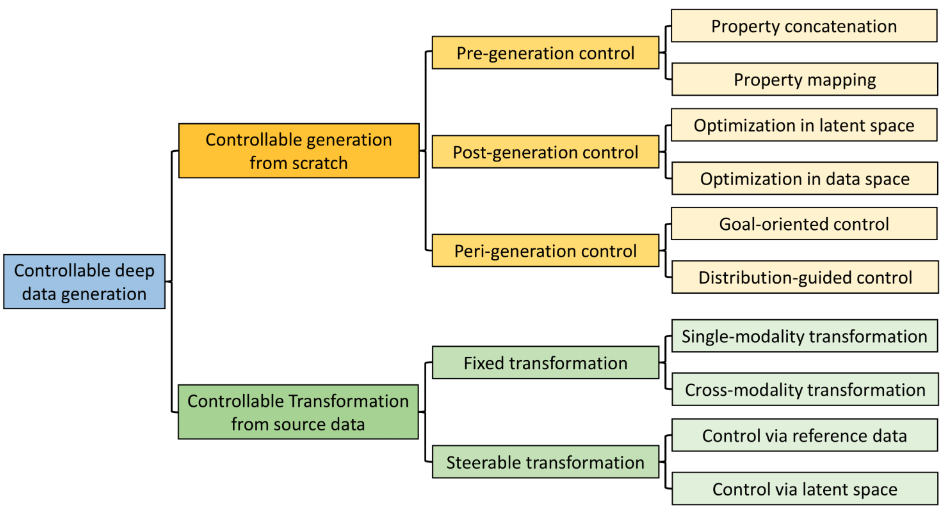
Figure 1: Controlled generation taxonomy.
Controlling data generation is classified into two classes, 1) data generation from scratch, and 2) transforming source data.
Controllable generation from scratch is further divided into three classes depending on when and how the control properties are fed into the generator.
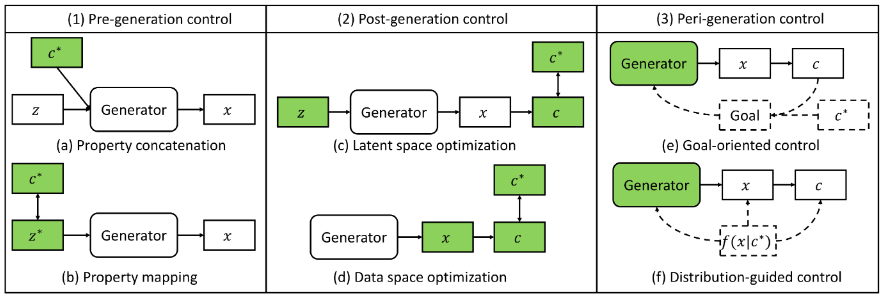
Figure 2: Controlled generation from scratch.
Pre-generation mechanisms set control properties as input to the generator.
- Property concatenation: Feeds property codes along with data representation into generator (e.g. diffusion guidance)
- Property mapping: Maps target properties into latent space and feeds embedding of target properties into generator (e.g. conditional sequential generation).
- Latent space optimization: Requires the model to learn optimized latent vectors that can be decoded to desired properties.
- Data space optimization: Modifies the generated data, e.g. kNN retrieval.
- Goal-oriented control: Optimizes the goal calculated by target properties of generated data in an iterative manner.
- Distribution-guided control: Bias the input data distribution towards the target distribution of desired properties (e.g. 3D molecular generation with target properties).
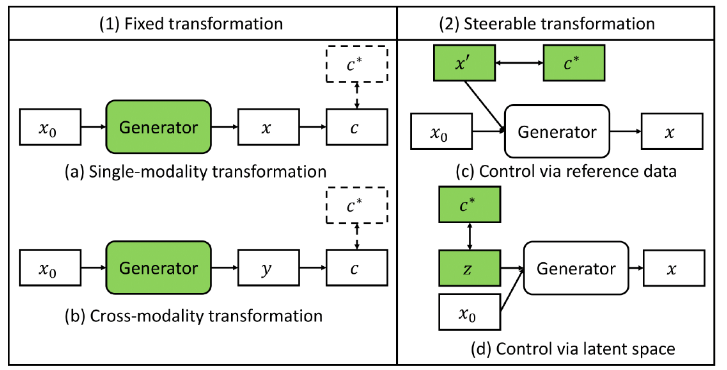
Figure 3: Controlled transformation from source data.
Transformation from source data can be either:
- Training a model to specialize on single transformation (e.g. day-time to night-time images).
- Training the model to perform many different transformations, generally indicated by a task embedding, and the user choose the transformation dynamically.
Xun et al (2024) [2] described the methods for controlling text generation. They categorized text generation control into two classes, controlling linguistic properties (e.g. vocabulary) and controlling content attributes (e.g. topic, semantic). The control mechanisms fall into two classes, training-time and inference time.
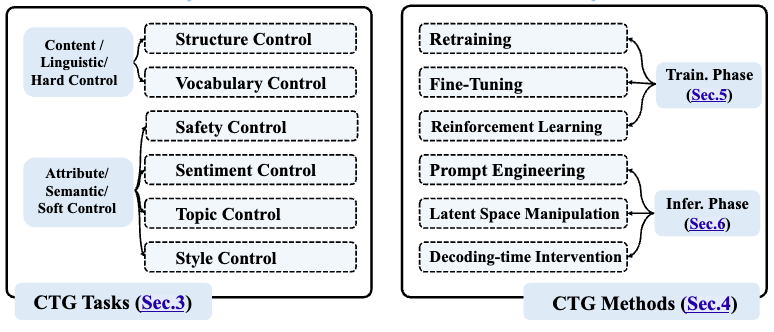
Figure 3: Controlled text generation.
Model Editing
Model editing (ME) updates a small proportion of knowledge, typically after deployment to fix errors or keep pace with changing knowledge in the world. Model editing aims to be very precise.
Song et al (2024) [3] discussed various knowledge editing techniques (figure 4). They first discussed evaluation metrics, which are accuracy, locality, generality, portability, retainability and scalability. They categorize ME methods into external memorization, global optimization and local modification.
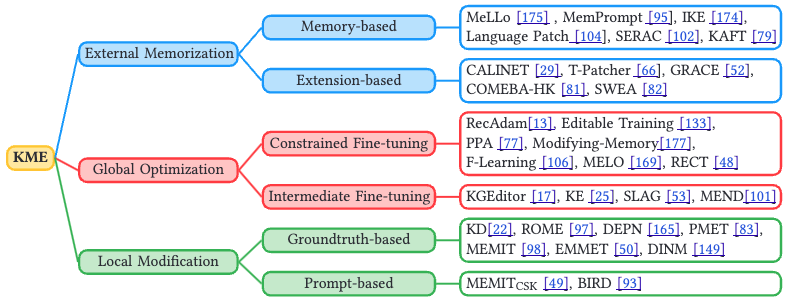
Figure 4: Model editing taxonomy.
External memorization leverages an external memory to store new knowledge. Global optimization employs generalizable incorporation of new knowledge into pre-trained LLMs. Local modification aims at locating related parameters of specific knowledge in LLMs.
Model Unlearning
Model unlearning aims to remove specific knowledge from a model, which might be required due to policy changes, privacy concerns or model drift.
Thanveer et al (2024) [4] discusses various machine unlearning approaches (figure 5).
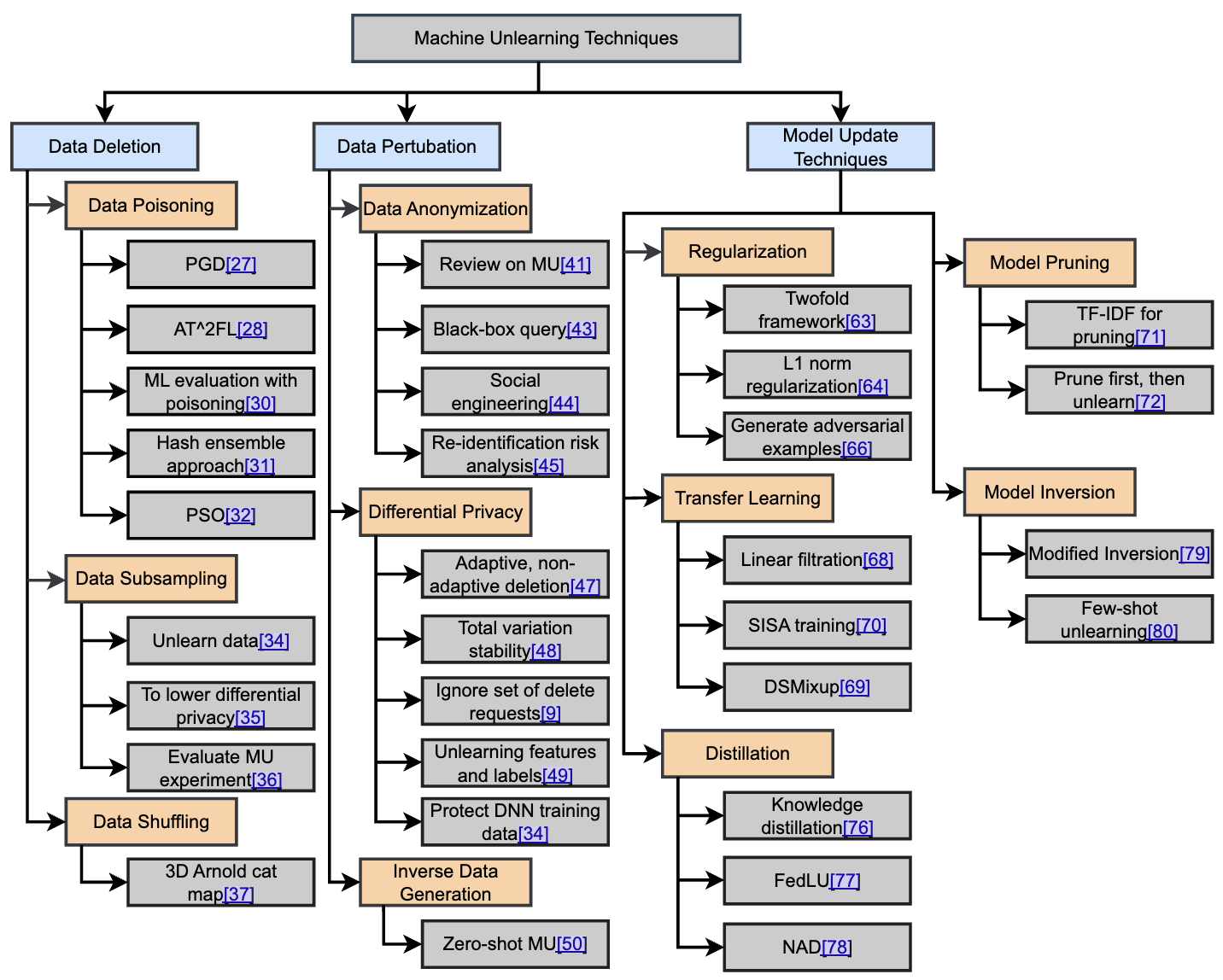
Figure 5: Model unlearning methods
Data deletion methods try to remove specific data from the knowledge of the trained model. Data poisoning is when an adversary inserts harmful data in training data. Techniques to mitigate data poisoning include projected gradient descent and hash ensemble approach. Data subsampling reduces the amount of data for model training. Data shuffling obscure sensitive information in a dataset by changing the order of the data points.
Data perturbation methods try to hide sensitive information in the training data. Data anonymization removes personally identifiable information. Anonymization techqniques include masking and generalization. Differential privacy protects sensitive data and provides privacy guarantees, while allowing accurate analysis on the data. This is generally achieved by adding noise to the data so that original data cannot be reconstructed. Inverse data generation generates a new dataset similar to original one without any sensitive information.
Model updating approaches include regularization, transfer learning, model pruning, knowledge distillation and mitigating model inversion. Model inversion reverse-engineers a model’s predictions to infer the characteristics of the underlying training data. Model inversion can be mitigated with differential privacy, regularization and adversarial training.
Interpreting AI Models
Vikas et al (2024) [5] discussed different types of mechanisms for explaining AI models (figure 6).
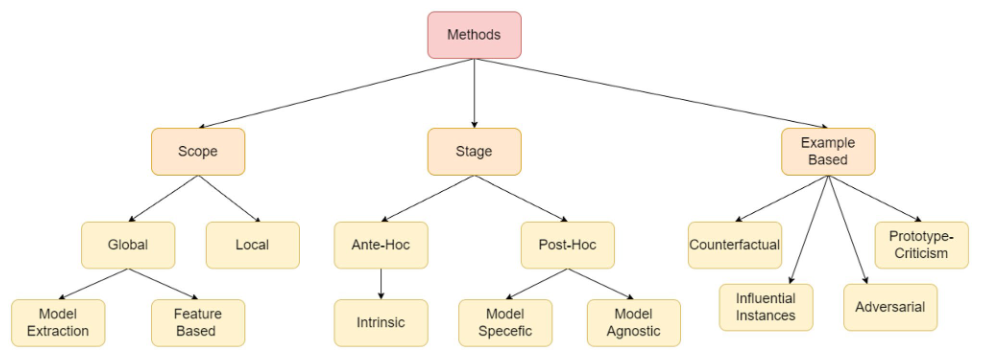
Figure 6: Model interpretation mechanisms
Local interpretability focuses on providing explanations separately for each choice. Examples are LIME, DeepLift, LRP, and Shapley.
Ante-hoc methods use an uncomplicated structure. Examples are linear regression, kNN, bayesian rule lists, decision trees. Post-hoc methods can be model-specific or model-agnostic. Model-agnostic methods are generally visualization. Examples are Partial Dependence Plot (PDP), Individual Conditional Expectation (ICE) (PCA, t-SNE, scatter plot, heat map), Accummulated Local Effects (ALE).
Example-based explanations include prototypes (representing all data), criticisms (making model mistake), counterfactual, adversarial examples. Some methods for visualization of individual examples are DGMTracker, GANViz, SCS, FRT, and saliency map (Grad-CAM).
References:
- Controllable Data Generation by Deep Learning: A Review, Shiyu et al, April 2024.
- Controllable Text Generation for Large Language Models: A Survey, Xun et al, Aug 2024.
- Knowledge Editing for Large Language Models: A survey, ACM Compute Survey, Song et al, Nov 2024.
- Exploring the Landscape of Machine Unlearning: A Comprehensive Survey and Taxonomy, Thanveer et al, 2024.
- Interpreting Black‑Box Models: A Review on Explainable Artificial Intelligence, Vikas et al, 2024.